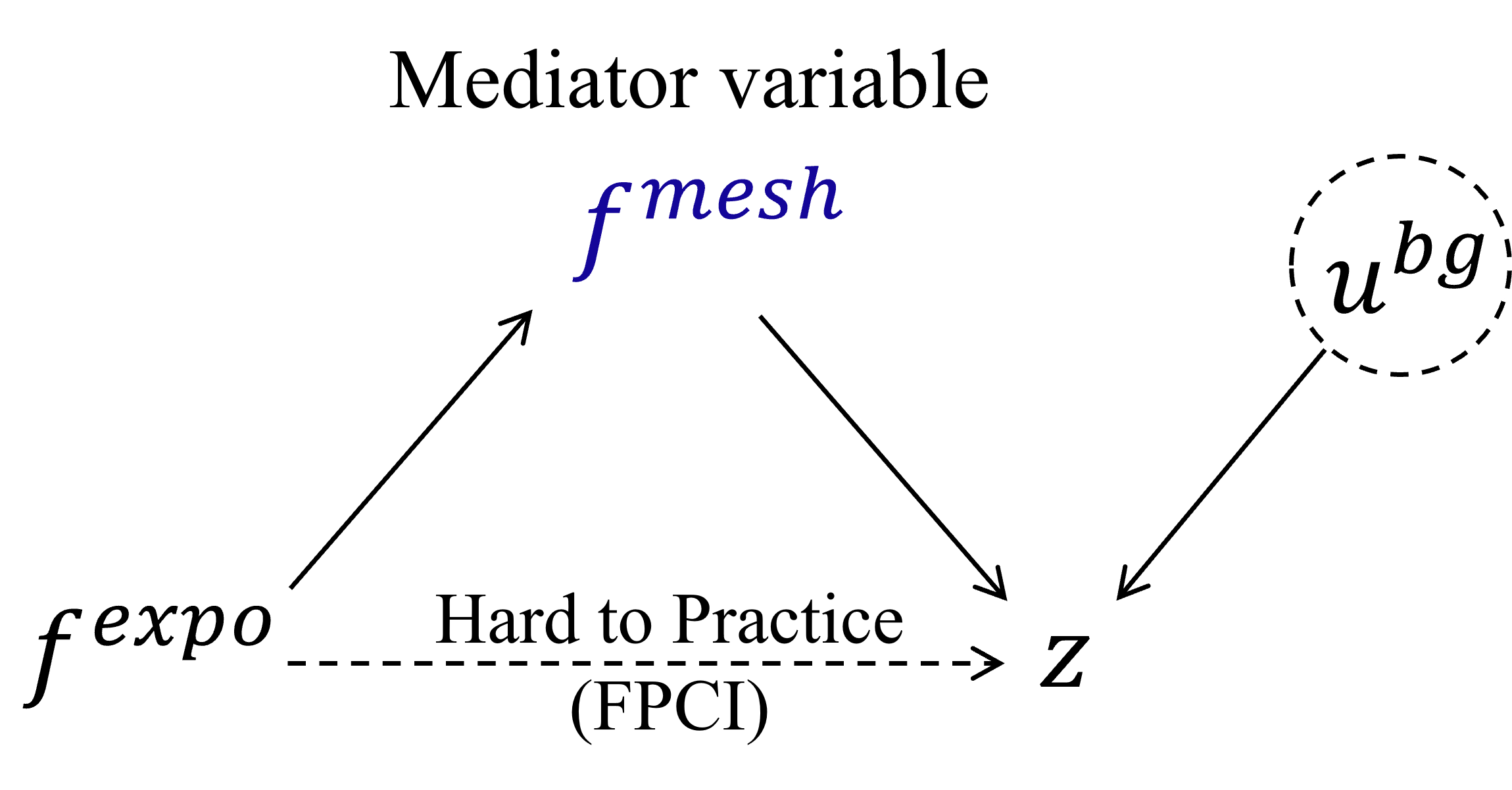Figure 1. Visual records from Gege's Ph.D. journey across Zürich and Tübingen.
About Me

Hello! I am an ELLIS Ph.D. candidate in Computer Science, advised by Prof. Andreas Geiger at University of Tübingen and Prof. Bernhard Schölkopf at ETH Zürich. My Ph.D. journey has taken me across Zürich and Tübingen, as illustrated in Fig. 1. Before that, I received my M.Sc. and B.Sc. in Applied Statistics.
I am a foundation-model researcher who designs principled alternatives to black-box generative systems, using structure, memory, and natural intelligence as modeling principles.
My research explores structured generative modeling: the idea that generation should not be treated as a single opaque mapping, but as an interpretable process that unfolds through semantically meaningful stages. Rather than focusing only on final outputs, I am interested in making the generative process itself a first-class object that can be inspected, controlled, and shaped by structure.
Looking ahead, I am interested in world models as hierarchical and evolving memory systems. In this view, a world model should not merely store past observations or predict the next frame; it should maintain semantic states that decide what to retain, what to abstract, what to evolve, and what to forget. This perspective connects long-context video generation, object-centric representation, causal structure, and scalable generative modeling.
Students / collaborators: If you are interested in generative models, feel free to reach out for research ideas or potential collaboration.
Mentoring
I am fortunate to work with some highly motivated and talented students:
- - Merve Kocabaş (2025 - present)
- - Research project student
- - Focus: controllability and interactivity
- - Marcel Plocher (2025 - present)
- - Master thesis student
- - Focus: training efficiency
Spring 2026, I received a compute award from the EuroHPC JU.
Summer 2025, I am TAing ML-4360.
Research
(† indicates project lead)
Click on a project to expand its abstract.
Slots, Transitions, Loops: Learning Object-Centric World Models for ARC
Under Review, 2026
Gege Gao†,
Bernhard Schölkopf,
Andreas Geiger
Abstract: ARC tests in-context rule induction: given a few input-output demonstrations, a model must infer the hidden rule and apply it to a new query. While many approaches express ARC rules through language, code, or symbolic programs, ARC itself is visual-symbolic: rules appear as grid transitions over objects, colors, shapes, and spatial relations. We introduce Loop-OWM, an object-centric world-modeling architecture that learns these rules as composable transitions over structured states. It combines color-prototype slots, demonstration-conditioned task summaries, and a looped transition model with dense propagation and slot-conditioned correction. On both ARC-1 and ARC-2, Loop-OWM outperforms non-looped and looped baselines with comparable or fewer parameters. These results suggest that ARC rules can be learned not only as language descriptions or searched programs, but also as transitions over visual-symbolic world states.
BibTeX:
@article{gao2026loopowm,
title = {Slots, Transitions, Loops: Learning Composable World Models for ARC},
author = {Gao, Gege and Schölkopf, Bernhard and Geiger, Andreas},
journal = {arXiv preprint arXiv:2606.12316},
year = {2026}
}
Trajectory Forcing: Structure-First Generation with Controllable Semantic Trajectories
ECCV 2026
Merve Kocabaş,
Gege Gao†,
Bernhard Schölkopf,
Andreas Geiger
Abstract: Diffusion and flow-based generative models typically treat generation as an opaque mapping from noise to image. Although recent methods have begun to exploit trajectory structure for improved quality, intermediate states remain uninterpretable and inaccessible to users. We propose Trajectory Forcing (TF), a framework that elevates the generative trajectory from a hidden computational process to an explicit, controllable object. Generation is organized as a sequence of semantically structured stages, progressing from global layout through object-level parts to fine-grained detail, where every intermediate state can be decoded, inspected, and edited. We construct coarse-to-fine teacher hierarchies via unsupervised clustering in pretrained, semantically meaningful representation spaces (e.g., DINOv2), and train a hierarchy-conditioned model using one-step flow matching at each level. We further introduce trajectory-aware evaluation measures that quantify structural consistency and local controllability beyond standard metrics such as FID. Experiments show that TF achieves competitive sample quality while producing structurally coherent, decodable intermediate states that support localized editing at each semantic level. By shifting the modeling focus from the final model outputs to generative dynamics, Trajectory Forcing enables controllable, trajectory-aware image synthesis.
BibTeX:
@Inproceedings{kocabas2026trajectoryforcing,
author = {Kocabas, Merve and Gao, Gege and Schölkopf, Bernhard and Geiger, Andreas},
title = {Trajectory Forcing: Structure-First Generation with Controllable Semantic Trajectories},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2026},
}
Echoes of the Prior: Visualizing the Decay of Machine Memory in 3D Reconstruction
SIGGRAPH 2026
Gege Gao†,
Bernhard Schölkopf,
Andreas Geiger
Abstract: Memory is not merely the storage of data; it is the scaffolding of reality. When biological memory fades, the world does not simply turn black; it regresses into an unrecognizable chaos. Echoes of the Prior is an interactive installation that attempts to visualize this subjective phenomenology of forgetting. By inducing controlled synaptic decay within a Feed-Forward 3D Reconstruction model, we simulate the erosion of the brain's predictive priors. We position the Neural Network not as a tool for engineering, but as a cognitive proxy - a silicon brain whose structural degeneration offers us a glimpse into the disorienting, poetic, and terrifying experience of losing one's grip on the world. Ultimately, we offer this framework as a catalyst, inviting the wider community to explore the uncharted potential of neuromorphic aesthetics in visualizing the fragility of intelligence.
BibTeX:
@article{gege2025decart,
title = {Echoes of the Prior: A Computational Phenomenology of Forgetting},
author = {Gao, Gege and Schölkopf, Bernhard and Geiger, Andreas},
journal = {Proc. ACM Comput. Graph. Interact. Tech. (SIGGRAPH)},
year = {2026}
}
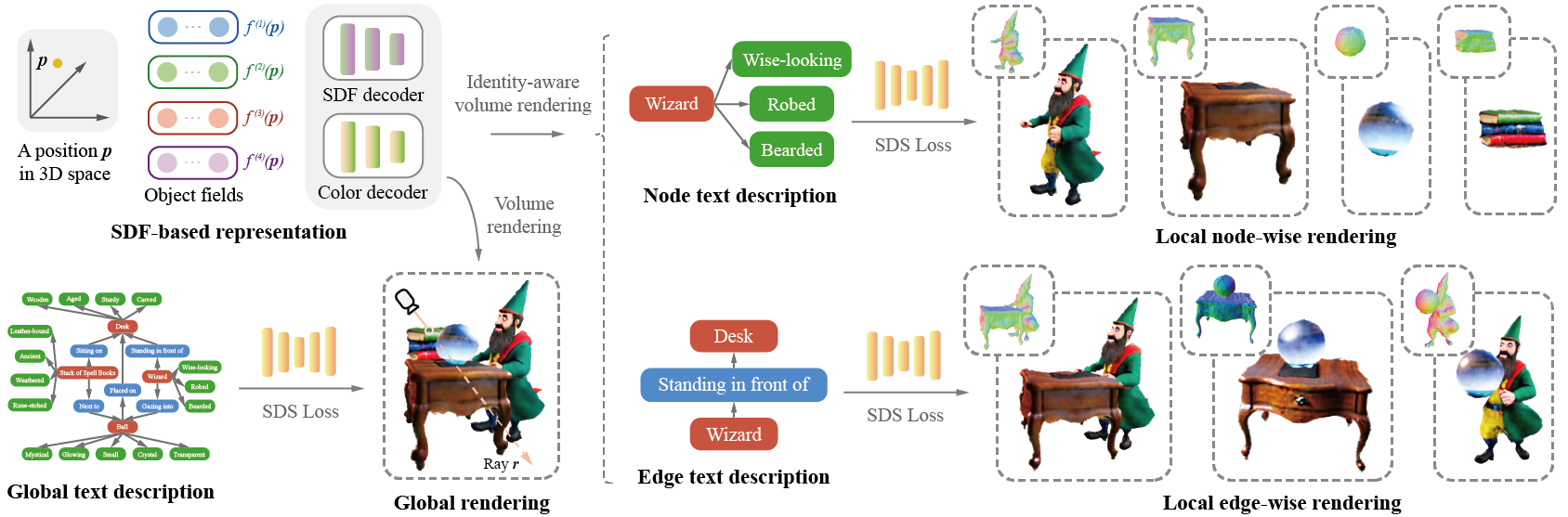
GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs
CVPR 2024
Gege Gao,
Weiyang Liu†,
Anpei Chen,
Andreas Geiger,
Bernhard Schölkopf
Abstract: As pretrained text-to-image diffusion models become increasingly powerful, recent efforts have been made to distill knowledge from these text-to-image pretrained models for optimizing a text-guided 3D model. Most of the existing methods generate a holistic 3D model from a plain text input. This can be problematic when the text describes a complex scene with multiple objects, because the vectorized text embeddings are inherently unable to capture a complex description with multiple entities and relationships. Holistic 3D modeling of the entire scene further prevents accurate grounding of text entities and concepts. To address this limitation, we propose GraphDreamer, a novel framework to generate compositional 3D scenes from scene graphs, where objects are represented as nodes and their interactions as edges. By exploiting node and edge information in scene graphs, our method makes better use of the pretrained text-to-image diffusion model and is able to fully disentangle different objects without image-level supervision. To facilitate modeling of object-wise relationships, we use signed distance fields as representation and impose a constraint to avoid inter-penetration of objects. To avoid manual scene graph creation, we design a text prompt for ChatGPT to generate scene graphs based on text inputs. We conduct both qualitative and quantitative experiments to validate the effectiveness of GraphDreamer in generating high-fidelity compositional 3D scenes with disentangled object entities.
BibTeX:
@Inproceedings{gao2024graphdreamer,
author = {Gao, Gege and Liu, Weiyang and Chen, Anpei and Geiger, Andreas and Schölkopf, Bernhard},
title = {GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
}
Causal Representation Learning for Context-Aware Face Transfer
Technical Report, 2021
Gege Gao,
Huaibo Huang, Chaoyou Fu, Ran He
Abstract: Human face synthesis involves transferring knowledge about the identity and identity-dependent shape of a human face to target face images where the context (e.g., facial expressions, head poses, and other background factors) may change dramatically. Human faces are non-rigid, so facial expression leads to deformation of face shape, and head pose also affects the face observed in 2D images. A key challenge in face transfer is to match the face with unobserved new contexts, adapting the identity-dependent face shape (IDFS) to different poses and expressions accordingly. In this work, we find a way to provide prior knowledge for generative models to reason about the appropriate appearance of a human face in response to various expressions and poses. We propose a novel context-aware face transfer model, called CarTrans, that incorporates causal effects of contextual factors into face representation, and thus is able to be aware of the uncertainty of new contexts. We estimate the effect of facial expression and head pose in terms of counterfactuals by designing a controlled intervention trial, thus avoiding the need for dense multi-view observations to cover the pose-expression space well. Moreover, we propose a kernel regression-based encoder that eliminates the identity specificity of the target face when encoding contextual information from the target image. The resulting method shows impressive performance, allowing fine-grained control over face shape and appearance under various contextual conditions.
BibTeX:
@article{gao2021causal,
author = {Gao, Gege and Huang, Huaibo and Fu, Chaoyou and He, Ran},
title = {Causal Representation Learning for Context-Aware Face Transfer},
journal = {arXiv preprint arXiv:2110.01571},
year = {2021}
}
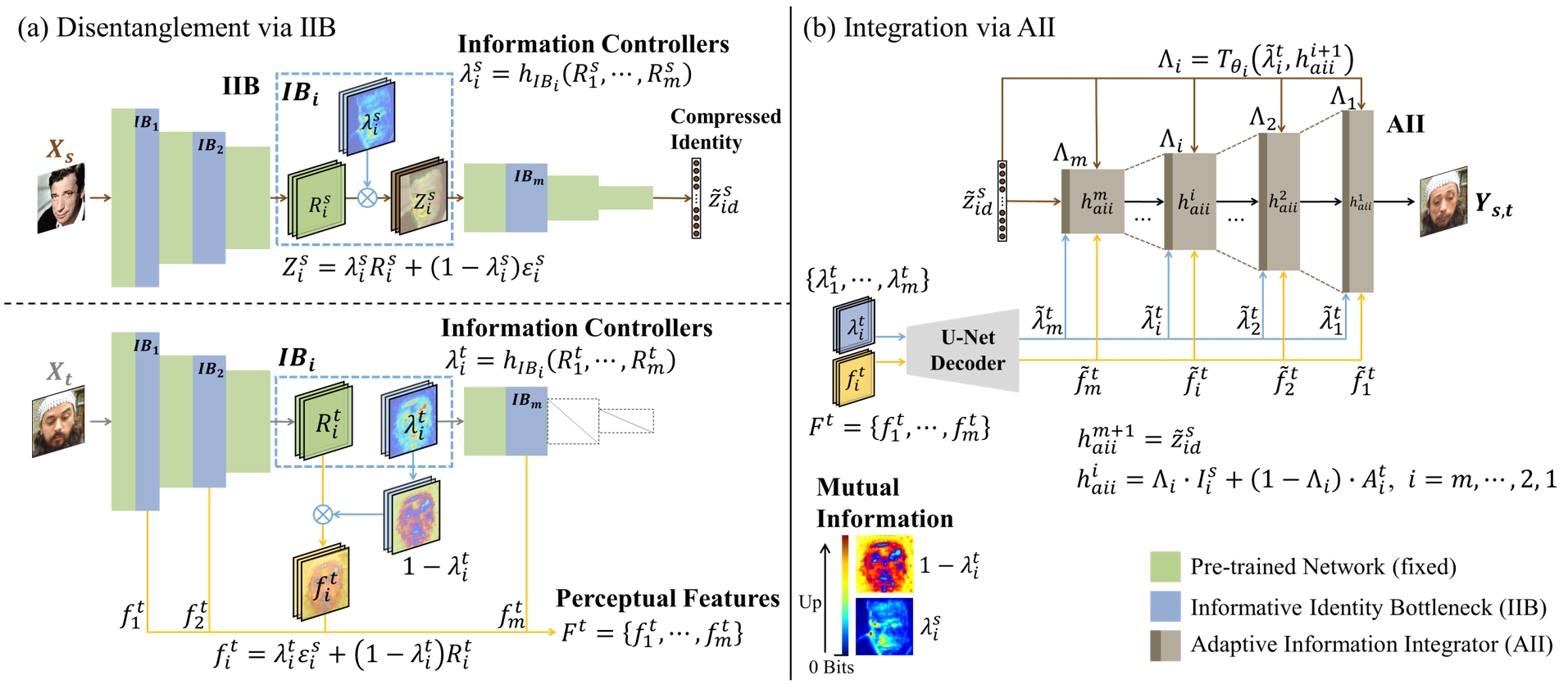
Information Bottleneck Disentanglement for Identity Swapping
CVPR 2021
Gege Gao,
Huaibo Huang, Chaoyou Fu, Zhaoyang Li, Ran He
Abstract: Improving the performance of face forgery detectors often requires more identity-swapped images of higher-quality. One core objective of identity swapping is to generate identity-discriminative faces that are distinct from the target while identical to the source. To this end, properly disentangling identity and identity-irrelevant information is critical and remains a challenging endeavor. In this work, we propose a novel information disentangling and swapping network, called InfoSwap, to extract the most expressive information for identity representation from a pre-trained face recognition model. The key insight of our method is to formulate the learning of disentangled representations as optimizing an information bottleneck trade-off, in terms of finding an optimal compression of the pre-trained latent features. Moreover, a novel identity contrastive loss is proposed for further disentanglement by requiring a proper distance between the generated identity and the target. While the most prior works have focused on using various loss functions to implicitly guide the learning of representations, we demonstrate that our model can provide explicit supervision for learning disentangled representations, achieving impressive performance in generating more identity-discriminative swapped faces.
BibTeX:
@InProceedings{Gao_2021_CVPR,
author = {Gao, Gege and Huang, Huaibo and Fu, Chaoyou and Li, Zhaoyang and He, Ran},
title = {Information Bottleneck Disentanglement for Identity Swapping},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {3404-3413}
}
Total - visits since April 2026